Word Error Rate vertelt over de nauwkeurigheid van het spraakherkenningssysteem
Word Error Rate (WER) is een veelgebruikte maatstaf om de nauwkeurigheid van spraakherkenningssystemen te evalueren. WER meet hoeveel fouten een spraakherkenningssysteem maakt bij het omzetten van spraak naar tekst. WER wordt berekend door de herkende tekst te vergelijken met het originele manuscript en door verschillen te identificeren, zoals toegevoegde, ontbrekende of verkeerd herkende woorden.
WER wordt als volgt berekend:
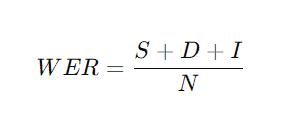
- S is verkeerd vervangen woorden (Insertions),
- D ontbrekende woorden (Deletions),
- I is ingevoegde woorden (Insertions),
- N is het aantal woorden in de originele tekst.
In de praktijk kan WER worden gebruikt om de prestaties van het spraakherkenningssysteem in verschillende gebruikssituaties te evalueren. Het is een belangrijke maatstaf bij het ontwikkelen en verbeteren van automatische spraakherkenningssystemen, die ook worden gebruikt als hulpmiddel bij bijvoorbeeld de ondertitelings- en transcriptiediensten van Spoken.
Hoe lager de WER, hoe nauwkeuriger het spraakherkenningssysteem. Het terugdringen van WER is daarom een primaire doelstelling voor bedrijven en onderzoekers die zich richten op het bevorderen van spraakherkenningstechnologie.
Whisper en WER-waarden voor verschillende talen
Bij Spoken gebruiken we het Whisper-spraakherkenningsmodel van OpenAI voor spraakherkenning, waarbij de WER-waarden variëren afhankelijk van de taal. Bij Engelse spraakherkenning is de WER doorgaans het laagste en dus het beste, vanwege de grote hoeveelheid beschikbare data en het feit dat het model is geoptimaliseerd voor de Engelse taal.
Voor Engels kan de WER zo laag zijn als 5–6%. Bij de Zweedse, Noorse en Deense spraakherkenning zijn de WER-waarden iets hoger, ongeveer 8–10%. In het Fins kan de WER zelfs nog hoger zijn, ongeveer 10–12%, vanwege de unieke structuur en morfologie van de Finse taal, die speciale uitdagingen met zich meebrengt voor spraakherkenningssystemen.
Uit deze vergelijking blijkt dat, hoewel Whisper voor veel talen zeer efficiënt is, de taalstructuur en de beschikbaarheid van gegevens een aanzienlijke impact hebben op WER.